Ideal for data journalists, investigative reporters, and sports analysts, Turboline Data Room simplifies the process of accessing, analyzing, and presenting data across multiple sources.
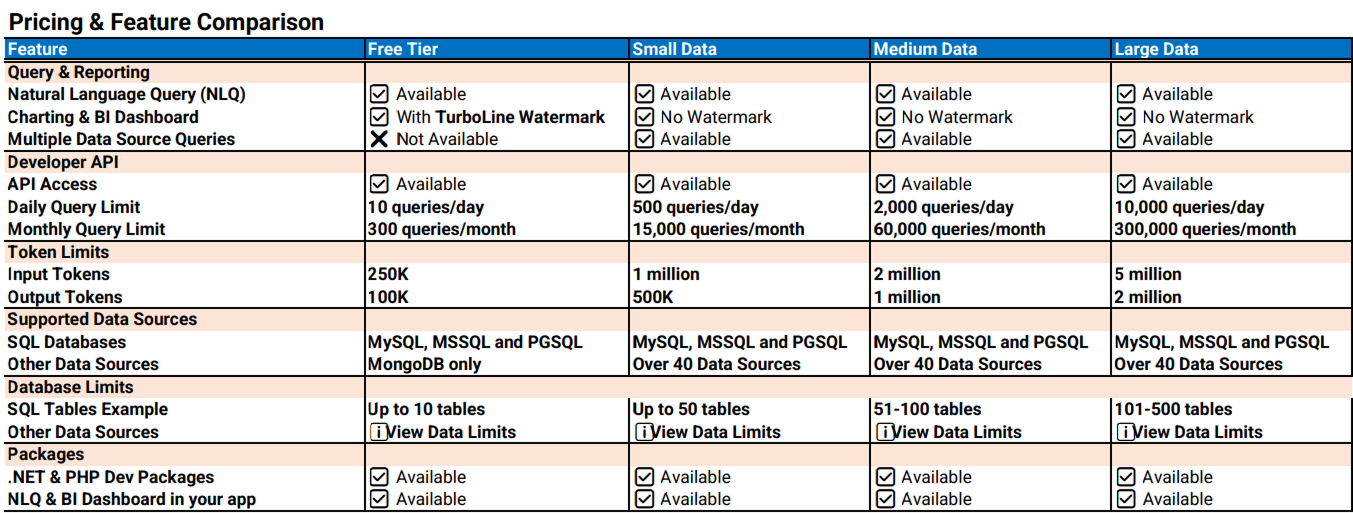
Some of our key features include:
-
Natural Language Querying – Search and analyze data using plain English, eliminating the need for SQL or technical training
-
Multi-Source Data Access – Connect to over 40 structured, semi-structured, and unstructured data sources
-
AI-Powered Query Engine – Built on Turboline’s proprietary AI Data Engine™, translating natural language into optimized queries
-
Customizable Dashboards and Visualizations – Build visual stories and reports with interactive charts and easy-to-use layout tools
-
Secure Deployment Options – Run the platform on your own infrastructure or in a fully managed cloud environment
-
Role-Based Access Control – Maintain data privacy and control through permission-based access settings
-
Data Export and Sharing Tools – Export insights and visuals in multiple formats for reports, articles, and presentations
-
Real-Time Performance – Designed to support fast-paced workflows, with low-latency query processing and dashboard updates
-
Optimized for Media and Research Workflows – Tailored for storytelling, investigation, and performance analytics use cases


Use Data Studio Today!
Natural language data analysis—SaaS or on your cloud.
Supported Database Sizes
| DB Tier | SQL DB (Tables) | NoSQL DB (Collections) | Redis (Keys) | Parquet / GeoParquet (Partitions) | CSV / JSON / XML (Files) | API Endpoints (REST/SOAP) | GraphQL (Complexity) |
|---|---|---|---|---|---|---|---|
| SmallDB | 0–50 tables | 0–10 collections <10 GB |
0–10,000 keys <5 GB |
0–10 partitions | 0–100 files <10 GB |
1–5 endpoints <100 KB |
1–3 shallow queries <1 MB |
| MediumDB | 51–100 tables | 11–50 collections <50 GB |
10,001–100,000 keys <20 GB |
11–50 partitions | 101–500 files <50 GB |
6–20 endpoints 100 KB–1 MB |
4–15 moderately nested queries 1–5 MB |
| LargeDB | 101–500 tables | 51–200 collections <200 GB |
100,001–1,000,000 keys <100 GB |
51–200 partitions | 501–2000 files <200 GB |
21–100 endpoints 1–10 MB |
16–50 deeply nested queries >5 MB |